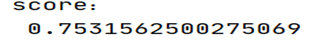实验内容 用湿度以及最低温度与最高温度建立二元线性回归模型
———爬虫,数据分析,可视化
实验环境 环境:python3.8,PyCharm
1 2 3 4 5 6 7 8 9 import requestsimport jsonimport reimport csvimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegression
实验步骤 数据爬取 爬取网站:http://www.weather.com.cn(中国天气网)
爬取城市以及时间:杭州9月近40天的天气
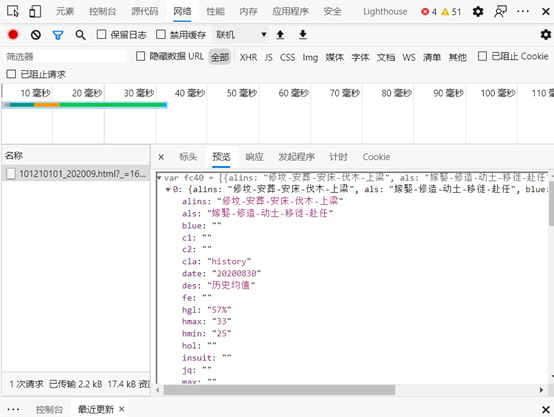
找到目标后,开始分析数据获取的接口。打开开发者网络选项卡,切换月份观察数据的加载。
可以看到我们找到了我们想要的接口,通过网页数据比对,可以知道其中就包含我们想要的数据,接下来分析接口的特点。
url中问号后方的请求参数下划线是时间戳可以忽略。101210101 是杭州的城市代码而202009 很明确是年份以及月份。以上,url的分析就到此为止,接下来进行请求头的分析。
通过测试我们确定了爬虫的请求头。
最后观察到返回文件中是js变量的数据格式,我们通过正则表达式和json库进行数据提取。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 def getData (year='2020' , month='09' ): header = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36 Edg/85.0.564.51' , 'Referer' : 'http://www.weather.com.cn/weather40d/101210101.shtml' } data = None try : r = requests.get("http://d1.weather.com.cn/calendar_new/2020/101210101_" + year + month + ".html" , headers=header) r.raise_for_status() r.encoding = r.apparent_encoding data = r.text except : print ("访问错误" ) exit(-1 ) pattern = re.compile (r"\[.*?\]" ) o = re.search(pattern, data).group() ret = json.loads(o) return ret def saveAsCSV (data, fields=None , saveName='data.csv' ): with open (saveName, 'w' , encoding='utf-8' , newline='' ) as f: if fields is None : writer = csv.DictWriter(f, fieldnames=data[0 ].keys(), delimiter=',' , extrasaction='ignore' ) else : writer = csv.DictWriter(f, fieldnames=fields, delimiter=',' , extrasaction='ignore' ) writer.writeheader() writer.writerows(data)
数据分析 本次我们要分析的数据是湿度,最高最低气温,因此我们保存数据为
1 2 3 saveAsCSV(source_data, fields=['date' , 'hgl' , 'hmax' , 'hmin' ])
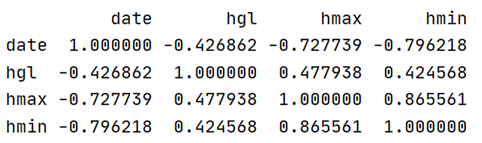
先观察数据的相关性(1正相关,-1负相关)
其实我们可以看出hgl和hmin与hmax的相关程度是挺差的(尤其是hgl),但是出于学习目的,我们先不用关心那么多,另一方面,更多方面的数据(气压等)目前我们还没渠道获取。
首先,对数据进行分组:
1 2 3 x_train, x_test, y_train, y_test = train_test_split(data[['hgl' , 'hmin' ]], data['hmax' ], train_size=0.65 )
建立模型进行拟合:
1 2 3 4 5 6 7 8 9 10 11 model = LinearRegression() model.fit(x_train, y_train) a = model.intercept_ b = model.coef_ print ('截距:\n' , a)print ('系数:\n' , b)score = model.score(x_test, y_test) print ('score:\n' , score)
根据R方可以看出拟合的效果不理想,这是预期之内的。
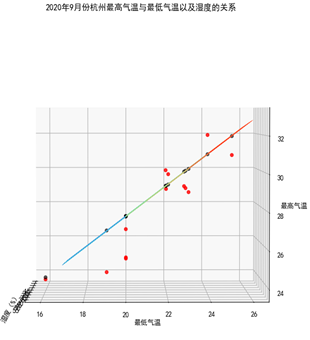
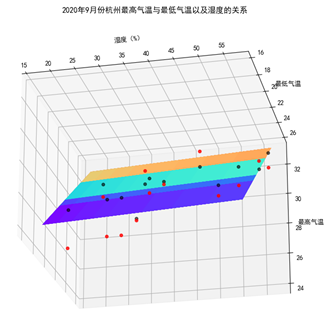
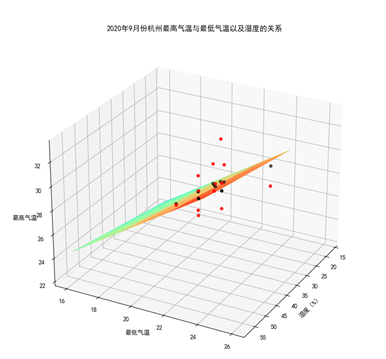
数据可视化 数据可视化没什么可以多讲的,需要注意的是本次我们采用的是二元线性回归,因此需要用到三维的数据可视化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 X = x_train['hgl' ] Y = x_train['hmin' ] X, Y = np.meshgrid(X, Y) Z = b[0 ] * X + b[1 ] * Y + a fig = plt.figure() ax = plt.axes(projection='3d' ) ax.plot_surface(X, Y, Z, cmap='rainbow' ,label='预测平面' ) ax.scatter(x_test['hgl' ],x_test['hmin' ],y_test,color='r' ,alpha=0.8 , label='实际值' ) ax.scatter(x_test['hgl' ],x_test['hmin' ],model.predict(x_test),color='k' ,alpha=0.6 , label='预测值' ) ax.set_xlabel('湿度(%)' ) ax.set_ylabel('最低气温' ) ax.set_zlabel('最高气温' ) plt.title('2020年9月份杭州最高气温与最低气温以及湿度的关系' )
实验结果
结果再次证明拟合不太理想,我们缺少更多的特征值,另一方面还是由于数据量太少(才只有40左右个数据)
通过本次实践,可知数据对于一个模型准确度的重要性,爬虫技术在数据分析中的地位十分重要,只有充足的数据种类和数量,才能保证我们能在大数据中发现一丝数据的意义。
参考文献
Python实现多元线性回归_ERICWONH的博客-CSDN博客 天气预报 :天气数据集爬取 + 可视化 + 13种模型预测_荣仔的博客-CSDN博客 R方和线性回归拟合优度_大数据部落-CSDN博客 线性回归模型笔记整理5 - 实战 多元线性回归程序示例 & 可视化_凤凰社 Order of Phoenix-CSDN博客 Python三维绘图–Matplotlib_TomRen-CSDN博客